Performance Measures
Accuracy
- Def: the fraction of correctly predicted classes out of all predictions
- Accuracy is not a good measure when a dataset is skewed - some classes are much more frequent than others.
1
cross_val_score(classifier, X, y, cv=k, scoring='accuracy')
Confusion Matrix
- it counts the number of times instances of class A are classified as class B
- Each row in a confusion matrix represents an actual class,
- while each column represents a predicted class
1
2
3
4
5
# get predicted labels for train
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, n_jobs=30)
# get confusion matrix
confusion_matrix(y_train_5, y_train_pred)
precision, recall and f1
- Precision
- the number of true positives(TP) divided by all positive predictions
- a measure of a classifier’s exactness
- Low precision indicates a high number of false positives.
- Recall
- the number of true positives(TP) divided by the number of actually positive values
- also called Sensitivity or the True Positive Rate (TPR)
- a measure of a classifier’s completeness
-
F1
-
the weighted average of precision and recall.
- \[f1=\frac{precision\cdot recall}{precision+recall}\]
-
Precision recall trade-off
Increasing precision reduces recall, and vice versa. This is called the precision/recall trade-off.
We could use P-R curve to select a good precision/recall trade-off.
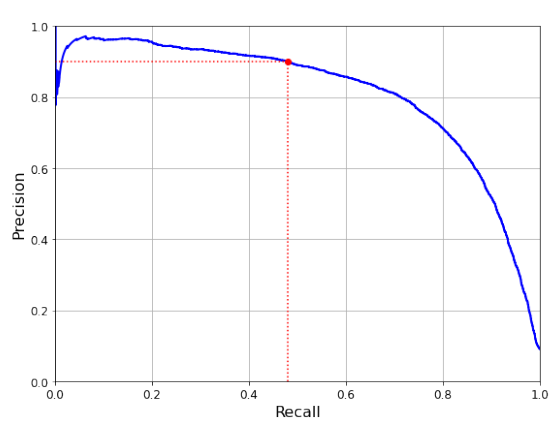
You can see that precision really starts to fall sharply around 80% recall. You will probably want to select a precision/recall trade-off just before that drop
ROC curve
- The receiver operating characteristic (ROC) curve is another common tool used with binary classifiers
- the ROC curve plots the true positive rate (TPR, another name for recall) against the false positive rate (FPR)
- The FPR is the ratio of negative instances that are incorrectly classified as positive.
- One way to compare classifiers is to measure the area under the curve (AUC).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function", n_jobs=30)
# PR curve
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.grid(True)
# roc curve
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate (Fall-Out)', fontsize=16)
plt.ylabel('True Positive Rate (Recall)', fontsize=16)
plt.grid(True)
# auc
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)
Classifier types
Binary Classifier
- y label is binary
- could use
- only for binary case: LR, SVM
- can deal with multiclass: SGD, rf, NB
Multiclass classifier
-
multiclass classifiers (also called multinomial classifiers) can distinguish between more than two classes
-
there are various strategies that you can use to perform multiclass classification with multiple binary classifiers. (Take MINIST classification problem as an exampl)
-
one-versus-the-rest (OvR)
- train 10 binary classifiers, one for each digit (a 0-detector, a 1-detector, a 2- detector, and so on)
- predict: get the decision score from each classifier for that image and you select the class whose classifier outputs the highest score.
-
one-versus-one (OvO)
- train a binary classifier for every pair of digits: one to distinguish 0s and 1s, another to distinguish 0s and 2s, another for 1s and 2s, and so on.
- If there are N classes, you need to train $\frac{N×(N–1)}{2}$ classifiers
- predict: run the image through all 45 classifiers and see which class wins the most duels
- adv: each classifier only needs to be trained on the part of the training set for the two classes that it must distinguish
-
How to choose
- Some algorithms (such as Support Vector Machine classifiers) scale poorly with the size of the training set. For these algorithms OvO is preferred because it is faster to train many classifiers on small training sets than to train few classifiers on large training sets.
- For most binary classification algorithms, however, OvR is preferred
1 2
from sklearn.multiclass import OneVsRestClassifier ovr_clf = OneVsRestClassifier(SVC(gamma="auto", random_state=42))
-
-
Error analysis
- could use confusion matrix
Multilabel classification
- the classifier outputs multiple binary tags for each instance
- example: Say the classifier has been trained to recognize three faces, Alice, Bob, and Charlie. Then when the classifier is shown a picture of Alice and Charlie, it should output [1, 0, 1] (meaning “Alice yes, Bob no, Charlie yes”).
1
2
3
4
5
6
7
8
9
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
# give concatenated ylabel
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
Multioutput Classification
- a generalization of multilabel classification where each label can be multiclass
1
2
3
4
5
6
7
8
9
10
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
-
Previous
Machine Learning: Deal with imbalanced data -
Next
Machine Learning: Model Training Algorithms