Study notes based on Liuge’s articles.
在数据分析中常会用到的方法论有:
- 方差分析
- 描述性分析
- 相关性分析
- 参数估计
- 幸存者偏差
- 辛普森悖论
- RFM分析模型
- AARRR模型
- SWOT矩阵(uncovered)
- MECE分析模型(uncovered)
- 漏斗分析模型(uncovered)
- 下钻分析(维度拆分)(uncovered)
本文将逐一梳理这些方法论的概念及应用情景。
描述性分析
描述性分析是用来测量和描述一个分布的各种统计量,可以分为集中趋势、离散程度、分布形状
| category | statistics | Notes |
|---|---|---|
| 集中趋势 | mode, median, quantile, mean | NULL |
| 离散程度(dispersion) | variation ratio(异众比率) | 非众数组的频数占总频数的比例;越大说明众数代表性越差; |
| Interquartile range(四分位距) | 四分位差不受极值的影响;一定程度上说明了中位数对一组数据的代表程度 | |
| 方差,标准差 | NULL | |
| coefficient of variation(离散系数) | \(cv=\frac{\sigma}{\mu}\); allow relative comparison of two measurement(单位不同) | |
| 分布形状 | skewness(偏度) | 样本的三阶标准化矩;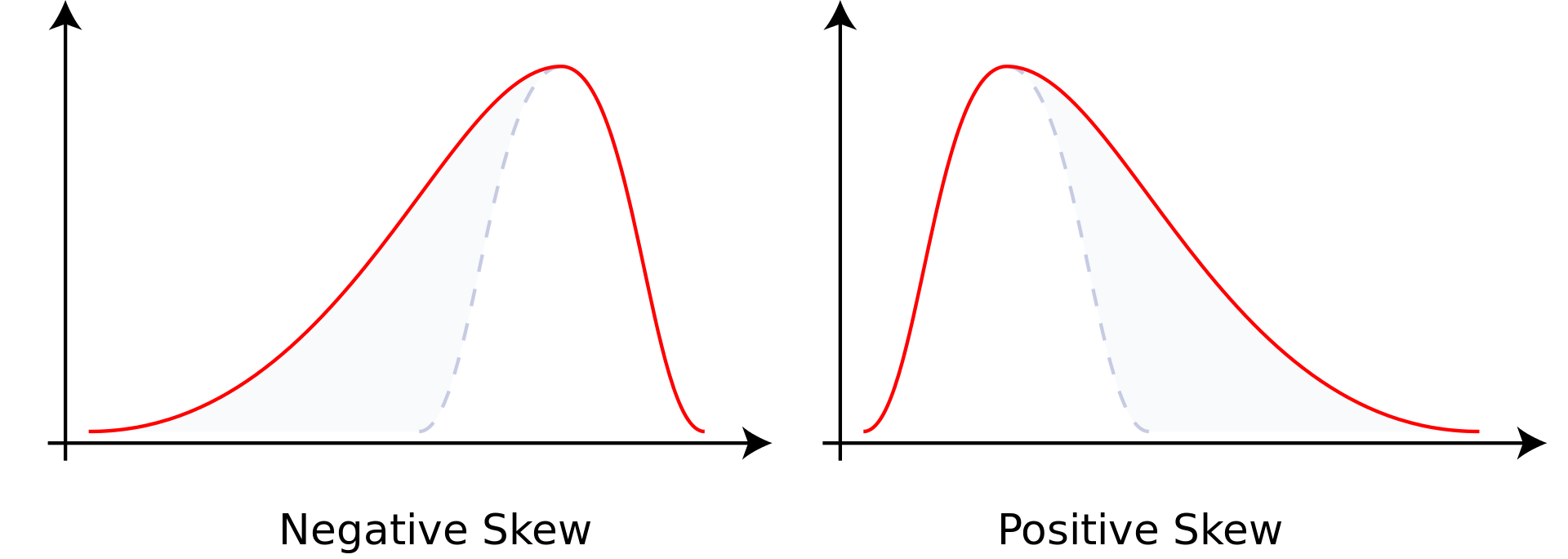 |
| Kurtosis(峰度) | 如果峰度大于三,峰的形状比较尖,比正态分布峰要陡峭 |
Example: 某电商平台用户的平均成交金额为20,成交金额的中位数为0,标准差为80,用户成交的分布呈现左偏长尾,请问从以上数据可以得出哪些结论?
Ans:
- 标准差是平均成交金额的4倍,说明用户成交金额较为分散
- 中位数为0元,说明平台一半以上的用户无成交记录
- 左偏长尾,说明存在大额成交用户,但是此种用户数量较少
相关性分析
| statistics | formula/value | use cases |
|---|---|---|
| Pearson | \(\rho_{X,Y}=\frac{cov(X,Y)}{\sigma_X\sigma_Y}\) | 两个变量之间是线性关系,且是连续数据;总体都是正态分布,或接近正态的单峰分布;两个变量的观测值是成对的,每对观测值之间相互独立。 |
| Kendall | 当τ为1时,表示两个随机变量拥有一致的等级相关性; 当τ为-1时,表示两个随机变量拥有完全相反的等级相关性; 当τ为0时,表示两个随机变量是相互独立的 | 有序分类的两个分类变量 |
| Spearman | 同上 |
Spearman correlation vs Kendall correlation
- In the normal case, Kendall correlation is more robust and efficient than Spearman correlation. It means that *Kendall correlation* is preferred when there are small samples or some outliers.
- Kendall correlation has a O(n^2) computation complexity comparing with O(n logn) of Spearman correlation, where n is the sample size.
- Spearman’s rho usually is larger than Kendall’s tau.
- The interpretation of Kendall’s tau in terms of the probabilities of observing the agreeable (concordant) and non-agreeable (discordant) pairs is very direct.
幸存者偏差
Defination
- 幸存者偏差(Survivorship Bias)指的是人通常会注意到某种经过筛选之后所产生的结果,同时忽略了这个筛选的过程,而被忽略的过程往往包含着关键性的信息。
-
Survivorship bias, survival bias or immortal time bias is the logical error of concentrating on the people or things that made it past some selection process and overlooking those that did not, typically because of their lack of visibility. This can lead to some false conclusions in several different ways. It is a form of selection bias.
- Interpretation
- 概率角度:条件概率。即,通常看到的结果,其实隐含前提假设,导致最终结论成立的条件被忽视掩盖;
- 样本角度:样本的代表性。即,观察到的部分样本,极有可能有偏,无法代表整体样本空间的特征,导致“以偏概全”的现象发生;
Common Situation
-
流失用户已静默
-
很多产品和数据分析师会将大量的分析工作放在了高活跃用户身上,根据二八原理,认为这些高活跃用户才是为平台带来收益的核心人群。于是,通过分析此类头部用户的行为,做出整体方案策略。但有时,上线后发现,效果往往并没有一开始预想的结果,甚至可能出现反向结论。
-
原因就在于,那些对平台功能、产品不满意的用户早已流失,分析师却将分析的重点仅放在了还在平台的高活跃用户身上。但这部分用户可能无论用户比重还是用户特性,都无法代表整体用户,因此可能造成策略 “失效”,这就是典型的幸存者偏差问题。
-
所以,为了策略整体效果,除了分析高活跃用户的行为,我们也应该聚焦分析流失用户的行为数据,比如
- 流失用户的事后调研、
- 流失前的行为识别等等
在权衡兼顾下,针对不同群体做出合适的策略,以提高平台整体效果。
-
-
发券策略虚假繁荣
- 为刺激用户消费,提高销平台售额,某电商平台产品在实验一期时对平台活跃用户进行发券。策略为:只要打开手机APP,用户即可发送弹窗,可领券固定面额的优惠券。后续发现优惠券的使用率较低。于是做了二期优化,二期针对查看过商品详情页信息的用户进行发券弹窗。实验发现,发券的使用率提升了200%。因此得出结论,应该对浏览过商品详情页的用户进行发券。
- 此结论就存在明显的幸存者偏差现象。
- 从打开手机APP 到 浏览过商品详情页,这一步骤,本身就存在漏斗转化的筛选:访问过商品详情页的用户相较前一漏斗的群体,有较强购买意愿,这类用户群体的转化率当然更高,继而发券使用率也更高。
- 可以辅助从用券数量(量级角度)摸底了解影响面,确保样本的完整性、代表性,而非直接使用“用券率”这种比率型指标,忽略量级,导致有失偏颇的结论发生。
How to avoid
-
分析前, 确保样本的随机性和完整代表性
- 样本随机性:分析下结论的过程中,必须确保统计的样本和未统计的样本不存在偏差,确保样本选取的随机性。
- 样本完整性:基于某种筛选的出来的样本分析得到的数据结果往往不可信,所以不要从一组不完整的数据中得出结论。要养成检测样本完整性、代表性的习惯。
-
分析中,保证客观公正的态度,学会自查验证:
-
客观姿态:在分析的过程中,往往更容易接受自己“期望”的结果。所以要始终保持客观公正态度,不能轻信所谓的直觉。
-
自查验证:
-
- 交叉验证:可以从多个维度进行交叉论证展开得到结论。
- 剩余样本:重视未使用样本,在分析的过程中,思考未使用样本的数据对当前结论是否有决定性的影响。这一步的论证非常依赖对业务的理解和把握。
-
辛普森悖论
Defination
- Simpson’s paradox, also called Yule-Simpson effect, in statistics, an effect that occurs when the marginal association between two categorical variables is qualitatively different from the partial association between the same two variables after controlling for one or more other variables.
-
在某个条件下的两组数据,分组研究时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。
- example:
- 昨天小李买了苹果和梨子,今天这两种水果的单价都涨价了。问:今日小李购买这两类水果,所花平均价格是否一定会上升?
- 极端假设情况:昨天,苹果卖2元/斤,梨子4元/斤,小李嗓子疼,只买了1斤梨子润润喉,均价花了4元;今天,苹果涨价到3元/斤,梨子5元/斤,小李觉得梨子卖的太贵了,就只买了1斤苹果,均价花了3元。因此,并不一定涨价了所买均价一定会提升~
Cause
具体解释就是:分组后其中的主要群组的影响权重更大,样本相对较小的群组单个看,虽然可能在数据指标上表现更高,但放在一起看,对于总体指标表现影响较小,即话语权较小,从而形成了辛普森悖论。
在上面的例子中,小李购买两类水果的均价,和每一类水果各自单价及购买斤数占比均有关。因此,小李想买的斤数就是其中的混杂变量,作为权重,其实影响着最终均价结果。
Common situation
【1】异常定位
对于某页面在9月份,男性女性用户点击率同比8月均增长,为何用户总体点击率下降?
【2】相关性分析
例如,想知道APP中某个频道的用户浏览次数与APP使用时长的关系,直觉上呈正相关,结果做回归模型发现相关关系为负,为什么?
【3】AB实验
例如,上了一个产品策略在灰度时效果是显著正的,结果全量了效果对全站影响为负
How to avoid
- 分析前:
- 所分析的问题是否有必要拆分维度?当数据与业务sense不一致时,再决定下钻拆分。
- 如果细分维度,如何选取维度?结合业务理解,判断哪些维度拆解具有实际业务指导意义。
- 分析中
- 辛普深悖论和各组样本量大小有关系,可以结合实际问题,定义个别分组的权重,用以消除基数差异影响。
-
可以结合全概率公式$P(B)=\sum_{i=1}^nP(A_i)P(B A_i)$ - 同时考虑各分组 “质” 和 “量” 的问题来做统一定量描述。
面试时,要注意一切看似简单的问题,其实可能涉及多变量,如果只说某一变量表现,问最终结果的问题都是在挖坑!
AAARRR模型
Overview
AAARRR stands for Awareness, Acquisition、Activation、Retention、Revenue、Referral.
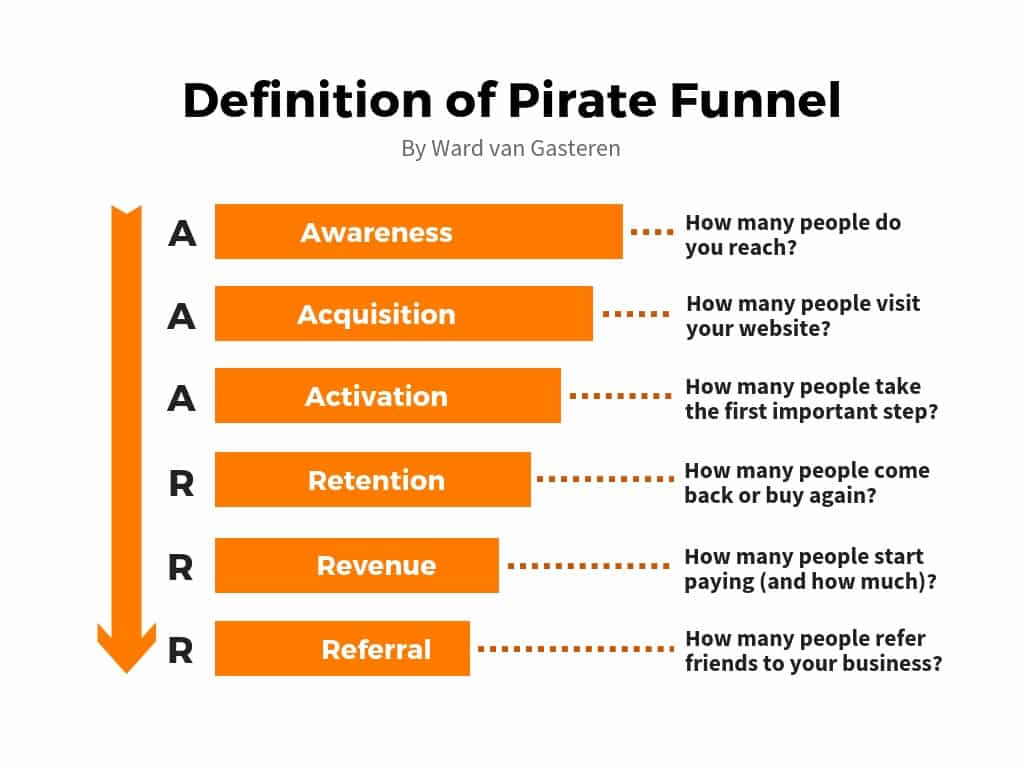
而在以上几个环节中,每个环节都有我们需要关注的指标,下面一一介绍。
Acquisition(获客)
- Meaning: 用户如何找到我们的产品、服务或品牌
- key factors:
- 载体:海报,电视剧,
- 渠道
- 口碑渠道:适合病毒式传播
- 自然流量:搜索引擎,内容营销等
- 付费传播:电视剧广告,赞助商等
- KPIs
- 渠道
- 自然流量:曝光量,转化率
- 付费流量:曝光量,转化率,成本
- 平台数据
- 新增用户数,APP下载量,平均获客成本
- 渠道
Activation(激活用户)
比如某电商平台,作为新用户如果需要完成首次购买行为,必须经历以下步骤:
- 下载APP,或微信小程序/网页
- 注册账号
- 找到想要购买的商品
- 加入购物车
- 输入收货地址
- 点击支付购买
在这一系列的动作中,作为BI,可以检测用户到底是哪一步漏斗转换较低导致最后转换失败:
- 是注册账号太麻烦?
- 还是用户找不到想要买的商品?
- 还是收货地址输入太费劲?
- 或者是支付环节不友好?
- 或者是价格太高等等?
只有优化整个产品体验,加大用户操作的便捷性,才能让用户更好的转换。
- 激活用户的措施
- 优化产品
- 小游戏
- 优惠券,降低用户购买的成本
- 新客优惠,设置新客优惠价,新客专享
- KPIs
- 在激活用户环节,最关键的就是有多少用户真正的使用了产品。我们将使用了产品的用户定义为活跃用户,比如电商平台的活跃用户即为购买用户。
- 活跃用户:日活,周活,月活
- 活跃用户占比(在总用户中)
- 访问深度
- 停留时长
Retention(用户留存)
对已经激活的用户,是否还愿意继续使用产品。
-
留存用户的措施
- 签到(获取积分)
- 小游戏,如蚂蚁森林
- 会员服务,如京东plus会员
- 这些服务的目标即希望用户养成打开和使用产品的习惯,类似京东的签到活动,即便是用户当下无购物需求,但是为了京豆还是愿意打开APP,和产品交互的过程,也、是激发用户购物的重要环节。
-
KPIs
- 次留
- 3日留存
- 7日留存
- N日留存
对于不同的业务和产品,到底看几日留存较为合适呢?这个要根据用户使用的频率来定义,比如对电商平台,次留,7日留存是非常关键的。对于即时通讯产品(如微信)次留是非常重要的。
Revenue(产品收入)
不同的产品实现盈利的方式不一样。
比如,电商平台通过商家抽佣、排序广告等方式实现盈利。
短视频平台作为流量分发机器,通过广告等实现盈利。据彭博社消息,字节跳动2020年广告收入1831亿元,从收入构成来看,广告依然是现金牛,占其2020年实际收入的77%。
-
KPIs
下面的核心指标对部分产品可能不适用。比如客单价适用电商平台,不适用微信平台。
- 用户:普通用户,付费用户,付费用户占比
- 广告收入:曝光,转换
- 用户价值:
- LTV(Lift time value): 用户首次注册账户到最后一次购买整个期间对平台的收入贡献。
- ARPU(Average revenue per user)
Referral(产品推荐)
推荐环节也叫病毒式营销,这一环节说明有多少用户愿意为产品进行宣传。
比如电影,通过朋友圈晒图,可以获取好评电影并激发用户购票观看的需求,所以对于电影行业来说,推荐环节至关重要。
- KPIs
- 分享次数
- 裂变层数
- 推荐曝光量
- 转化率
RFM模型
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。
在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。该模型涉及到以下三个变量:
- R-最近一次消费距当前的时长(Recency)
- F-消费频率(Frequency)
- M-消费金额(Monetary)
这篇文章中有详细举例和分析。
Example: 在电商领域,对重要挽留客户有哪些措施可以进行干预?
- 流失原因:首先可以通过电话调研确认用户流失的原因
- 营销手段:采取营销手段进行干预挽留,比如发放优惠券、低价商品引流
- 产品优化:如果是产品或者功能上的问题,可以通过优化产品提高用户体验减少流失
波士顿矩阵
波士顿矩阵通过销售增长率和市场占有率两个指标对公司和产品进行四象限分类。

具体分析方法